
Graphcore ResNet-50: A Powerful New Alternative to Nvidia's DGX-A100 for AI

Nvidia’s DGX-A100 system is considered the cutting-edge solution for large-scale AI training and inference workloads. However, a new startup called Graphcore may have just changed the game.
In recent head-to-head benchmarks, Graphcore claimed their IPU systems significantly outperform the DGX-A100 for popular CNN and NLP models. Their IPU-M2000 delivered over 2.5x faster ResNet-50 training and 4.6x faster inference throughput.
Even more impressive was Graphcore’s IPU-Pod64 rack scale system with 64 IPU chips. It surpassed the performance of 1-2 complete DGX-A100 racks running the same workloads.
How does the Graphcore IPU achieve this level of performance?
Graphcore designed their Intelligence Processing Unit (IPU) chip from the ground up for AI. With thousands of simple but fast cores in a massively parallel architecture, the IPU is highly optimized for the matrix math operations at the heart of modern deep learning models.
In contrast, GPUs like the A100 were originally created for graphics and have been adapted for AI secondarily. The IPU lacks legacy architectures holding it back from fully exploiting AI acceleration opportunities.

Graphcore claims a 1.6x advantage over NVIDIA, but did not provide an “Open” division result. Their benchmark completion time of 37.12 minutes outperforms NVIDIA’s DGX A100’s 28.77 minutes in the 1.0-1059 benchmark. The Inspur NF5488A5 result shows 27.48 minutes using AMD CPUs. Another OEM is also working on a system with 500W GPUs, with a review and YouTube video expected in July.
Here is what the 8x NVIDIA A100 80GB 500W nvidia-smi looks like:
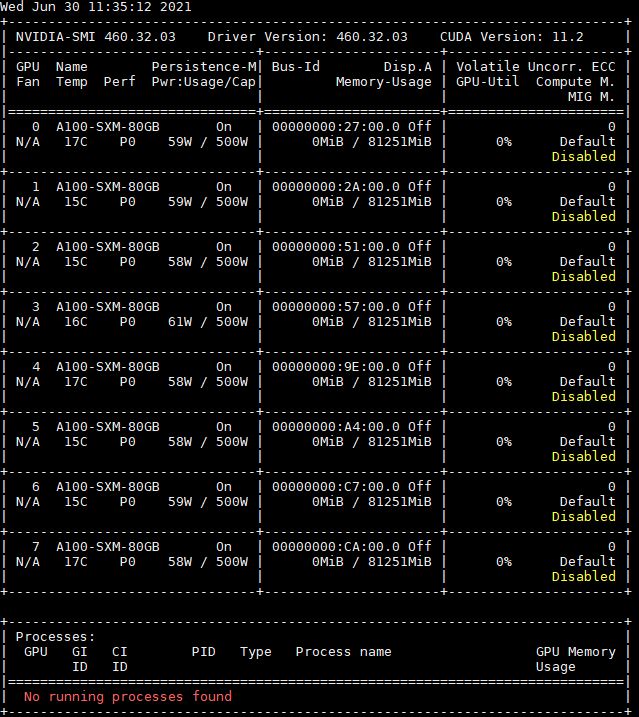
Here is the 40GB 400W version for comparison:
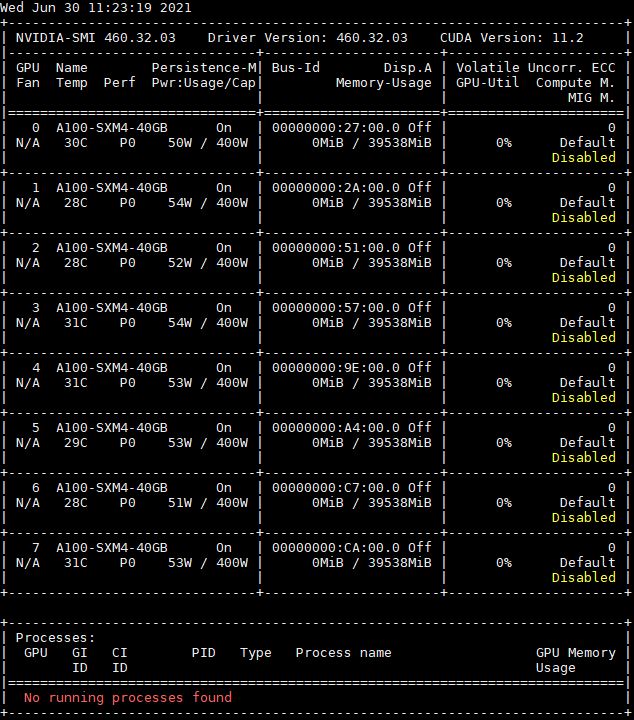
For now, the 500W A100 is a bit of a different solution, so it is most relevant to use the 80GB 400W systems for the top-of-line NVIDIA to Graphcore comparison, not the 500W parts. One will notice that the Supermicro SYS-420GP-TNAR+ result 1.0-1085 is slightly faster than the NVIDIA DGX result that Graphcore is comparing its IPU-POD16 to. This is important and we will get to that in a bit.
Graphcore MLPerf results: Open and Closed divisions

The results show how well Graphcore systems perform, even on the out-the-box closed division, with its restrictive specifications.
Even more impressive are the results in the open division, where we are able to deploy the sort of optimisations that make the most of our IPU and system capabilities. These more closely reflect real-world use cases, where customers can take advantage of available performance improvements.
Learn more about Accelerating ResNet-50 Traning on the IPU for MLPERF: https://www.graphcore.ai/posts/accelerating-resnet50-training-on-the-ipu-behind-our-mlperf-benchmark
Graphcore brings new competition to Nvidia in latest MLPerf AI benchmarks: https://www.zdnet.com/article/graphcore-brings-new-competition-to-nvidia-in-latest-mlperf-ai-benchmarks/
Why Choose Graphcore ResNet-50?
- Unlocking the potential of advanced models
In the benchmarks, Graphcore showed the IPU’s ability to efficiently train and run huge models like BERT, Mask R-CNN and GPT-3 up to 10x faster than alternatives. This scale of performance leaves room to experiment with even larger, more complex NN designs.
Flexibility and ease of use
Graphcore’s IPU software stack provides an intuitive Python API with integrated tooling for workload profiling and optimization. Combined with the IPU’s flexible architecture, this makes it easy for researchers to rapidly iteratively on new ideas.
In summary, Graphcore’s IPU is redefining the gold standard for AI hardware. As their technology matures, the IPU looks poised to compete strongly against Nvidia’s dominance in this booming market. Stay tuned for more benchmarks showing its capabilities.
About ATech Communication (HK) Limited
ATech Communication (HK) Ltd is one of the leading IT equipment & service provides for HKSAR Government Departments and Bureaux. We provide the best value and the best IT solution to our customers. Please visit our Cases page to learn more about our successful works. For more information on ATech, please contact us at enquiry@atechcom.net.


ATech Communication (HK) Limited
Providing a Complete Suite of IT Solutions
- (852) 2970 6010 / 3756 0078
- enquiry@atechcom.net

